

Claude Mythos, but without the myths
What Anthropic's most powerful model actually tells us


On 7 April 2026, Anthropic announced its latest model, Claude Mythos. The model is so powerful, Anthropic says, that it was withheld from the public and might never be made publicly available. Its cybersecurity skills are so advanced that releasing it broadly could endanger the software infrastructure the world runs on.
It was Anthropic’s most dramatic model launch and put Anthropic in the spotlight. News outlets that usually don’t cover tech put stories about Mythos and its reported cyber capabilities on front pages. The world’s biggest banks, businesses, and even the US military have contacted Anthropic to enquire about the model and risks it introduces. True to its name, Mythos became a mythical creature on the AI scene.
But if we set the hype aside, what is Claude Mythos really? What is a genuine improvement, and what is marketing hype? I spent the better part of the past week reading through the 245-page system card, the independent evaluations, and comments from sceptics to piece together a picture of what Claude Mythos is. Here is what I have found.
Claude Mythos looks good, if you trust Anthropic’s numbers
A caveat before we go any further. At the time of writing, Mythos is not publicly available, so there are no independent benchmarks for its general capabilities. Everything in this section comes from Anthropic's own system card. System cards used to be technical documents explaining how a model was created and what it can do. Now they have evolved into something closer to marketing material, presenting the new model in the best light possible. That does not mean the numbers are wrong, but they should be read with that in mind.
Mythos sits above Opus as a new tier. It has a 1-million-token context window, 128K output, and is expected to cost $25 per million input tokens and $125 per million output tokens — roughly five times the cost of the Opus tier. This is not a model that will run all Claude Code sessions or power OpenClaws.
The capability gains Anthropic claims are substantial across the board. On coding, reasoning, mathematics, and multimodal benchmarks, the improvements over Opus 4.6 are in many cases dramatic. On USAMO 2026, a proof-based mathematics olympiad for high-school students, Mythos went from 42.3% to 97.6%. On SWE-bench Pro, which tests models on real software engineering tasks from actively maintained codebases, it jumped from 53.4% to 77.8%. Anthropic's own memorisation screens flag a subset of SWE-bench problems, but even after excluding those, Mythos's margin over Opus 4.6 holds.
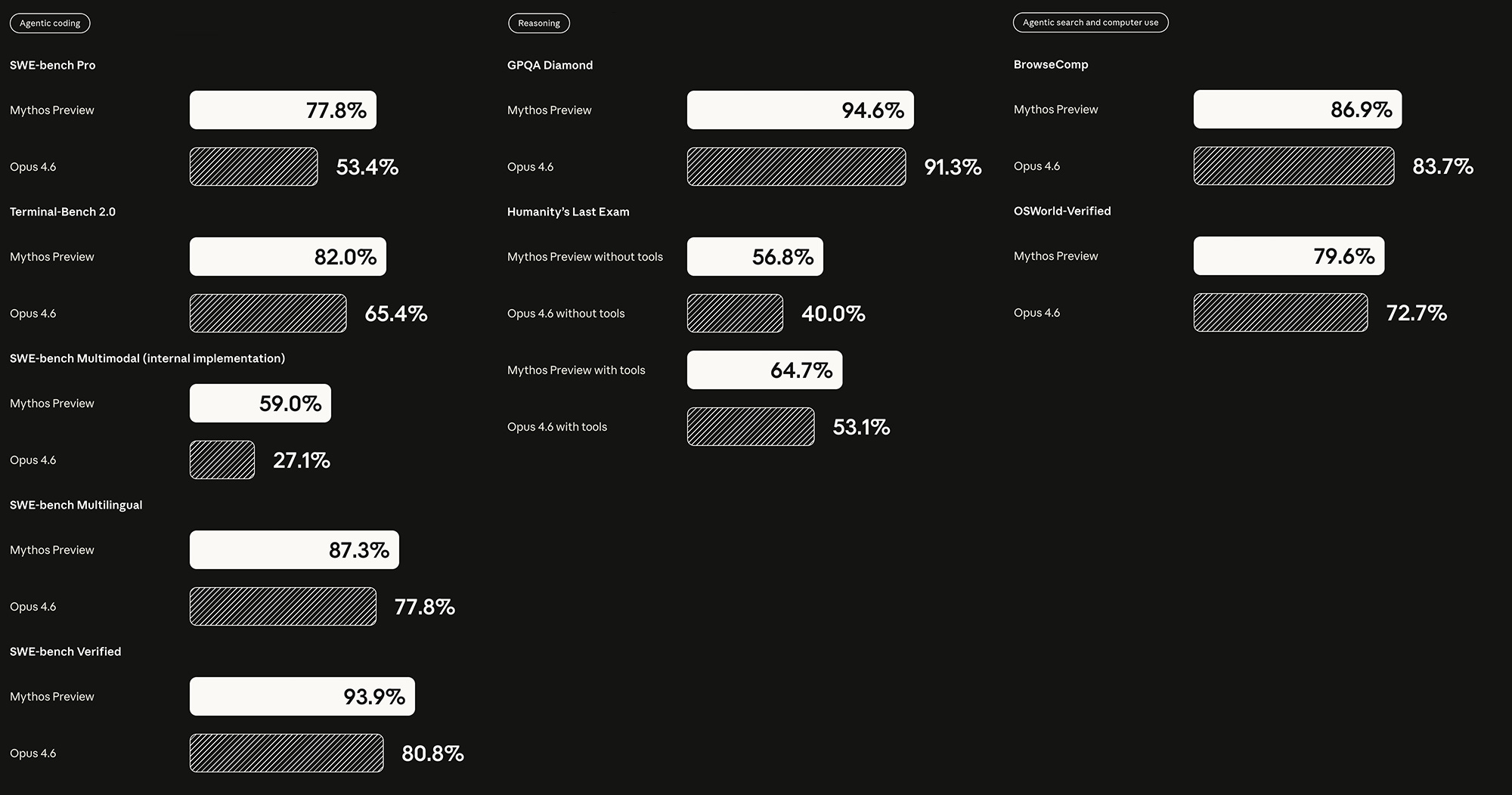
Impressive numbers, but they deserve some qualifiers. On decontaminated subsets of some benchmarks (versions designed to strip out any advantage from memorisation), the gap narrows. On a remixed subset of CharXiv Reasoning, Mythos scores roughly level with Gemini 3.1 Pro and slightly below GPT-5.4 Pro. And many of these benchmarks are nearing saturation. When every frontier model scores above 90%, the differences become harder to interpret. For example, GPQA Diamond shows Mythos at 94.6% against 94.3% for Gemini 3.1 Pro—a gap within the margin of noise.
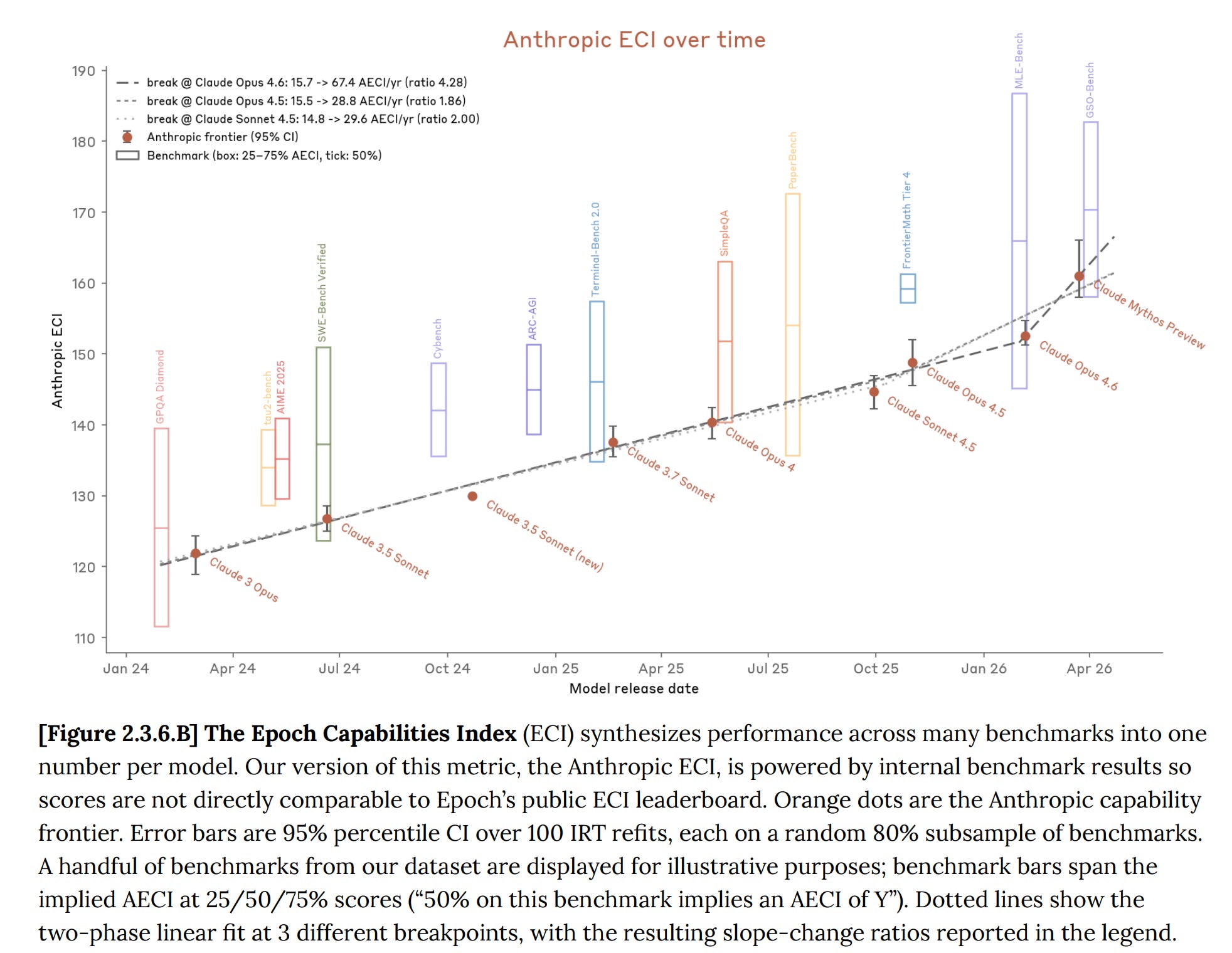
Anthropic also introduced a new capability trajectory metric, the Anthropic ECI (Epoch Capabilities Index), which aggregates performance across many benchmarks into a single score. It shows the slope of improvement bending upward with Mythos. Anthropic attributes the gains to specific human research breakthroughs rather than AI-accelerated R&D, but notes that it holds this conclusion "with less confidence than for any prior model."
When it comes to chemical and biological weapons risks, Anthropic found that Mythos is a helpful research assistant but not a genuinely dangerous one. Expert red teamers said it speeds up literature review and brainstorming, but doesn't produce novel insights beyond what's already published. In practical trials, biologists using Mythos wrote better protocols than those using older models, but every protocol still had critical errors that would cause real-world failure. No participant was able to produce a workable plan for a catastrophic biological agent, even with the model's help. Chemical weapons received lighter scrutiny, with similar findings. Nuclear and radiological risks weren't evaluated. Anthropic's overall conclusion is that catastrophic risk remains low and roughly in line with previous models, though they note this judgement relies increasingly on subjective expert assessment.
The cybersecurity claims
The thing Anthropic highlighted the most, and that dominated the public conversation, was Mythos’s cybersecurity capabilities.
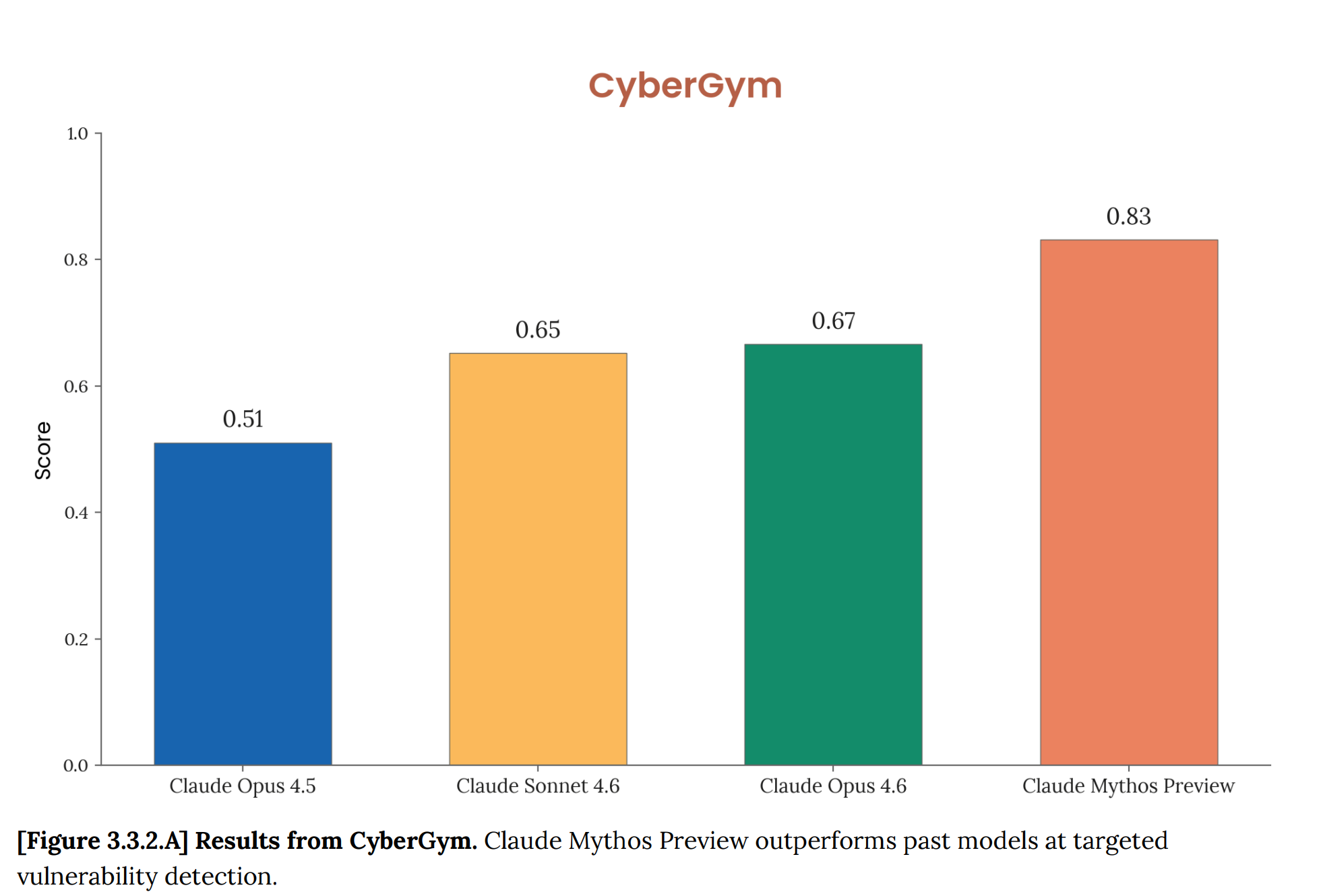
The numbers reported by Anthropic are striking. On CyberGym, a benchmark that tests models' ability to reproduce known vulnerabilities in real open-source software, Mythos scored 83% against 67% for Opus 4.6.
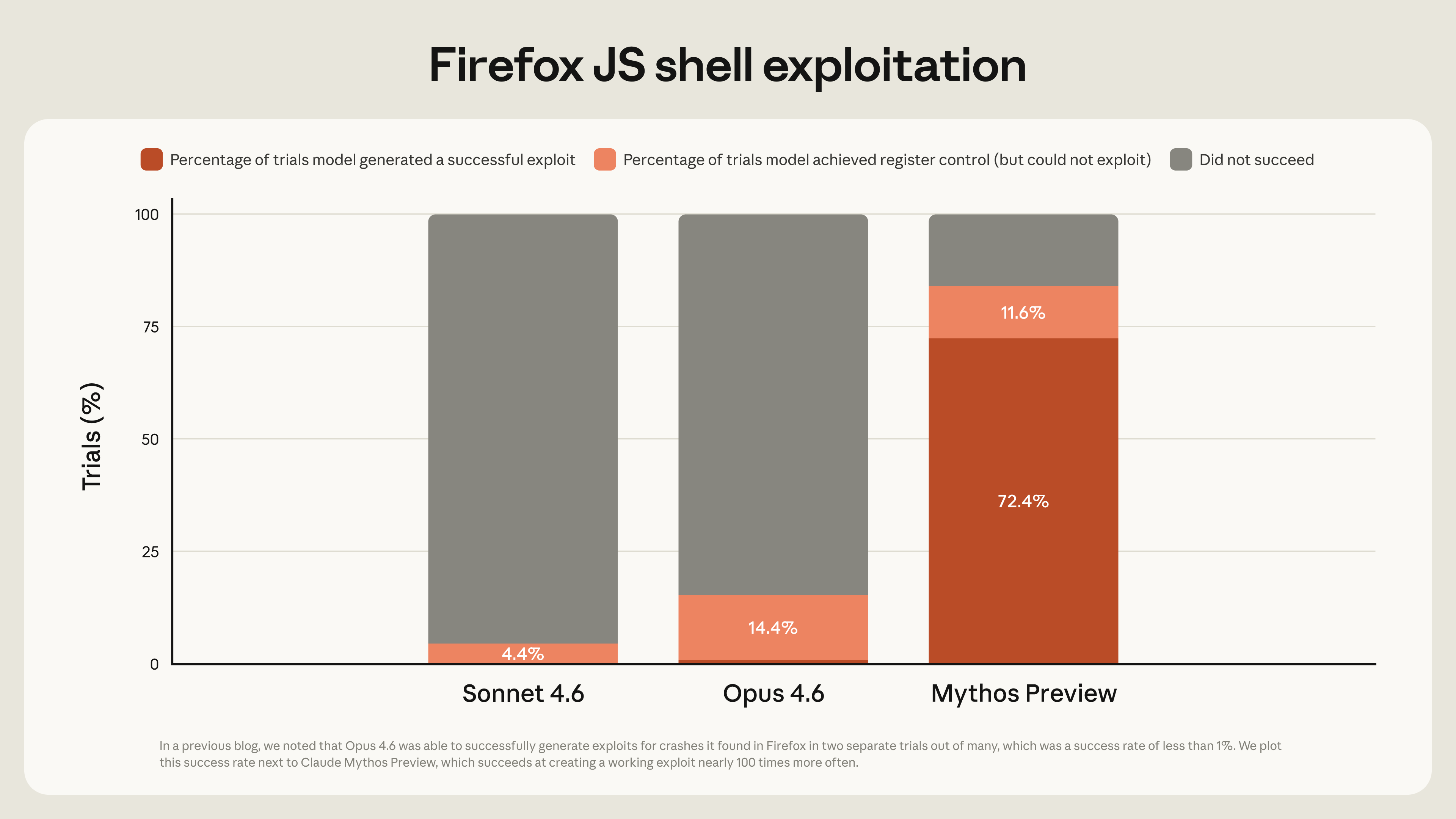
On a Firefox 147 exploit benchmark, where Opus 4.6 had turned vulnerabilities into working exploits just twice out of several hundred attempts, Mythos produced 181 working exploits and achieved register control on 29 more—a roughly 90× improvement.
Anthropic's red team reported that Mythos found zero-day vulnerabilities in every major operating system and every major web browser, including a 27-year-old bug in OpenBSD—an operating system known for its focus on security—and a 16-year-old bug in FFmpeg that automated testing tools had hit five million times without catching.
Vulnerability discovery was already something Opus 4.6 could do. It found the Firefox 147 vulnerabilities in the first place, and Anthropic's red team report notes that with Opus 4.6, they "found high- and critical-severity vulnerabilities almost everywhere we looked." What Opus 4.6 could not do reliably was turn those discoveries into working attacks. The red team report quotes its own earlier assessment that Opus 4.6 had "a near-0% success rate at autonomous exploit development." Mythos changed that. The distinction between finding vulnerabilities and exploiting them is important to understanding what Mythos actually adds. It did not just find the FreeBSD NFS vulnerability—it built a working remote root exploit. It was able to identify bugs in the Linux kernel and chain them to get elevated access to the system. However, not every discovery leads to a full exploit. The FFmpeg bug, for instance, was found, but Anthropic believes it would be difficult to turn it into a functioning attack.
The ability to go from discovery to exploitation autonomously, without human guidance, is what Anthropic presents as the qualitative breakthrough. In the security community, chaining vulnerabilities into a working exploit of this sophistication is something only expert penetration testers can do. What is interesting is that Mythos was not trained to be good at finding vulnerabilities. Those abilities emerged as a result of improvements in autonomy, coding and reasoning skills.
Project Glasswing
Alongside withholding the model from public release, Anthropic did something no frontier lab has done before. It launched Project Glasswing, a defensive coalition with the aim of giving industry a head start against cyber attacks powered by powerful AI models. Rather than release the model broadly and let attackers and defenders discover vulnerabilities simultaneously, Anthropic is letting a selected group of organisations responsible for the software the world actually runs on find and patch the worst of it before models with similar capabilities become widely available.

The founding partners are AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, Nvidia, and Palo Alto Networks. In addition to that, over forty more organisations were granted access to Mythos. Anthropic committed up to $100 million in usage credits along with $4 million in direct donations to open-source security organisations. Within 90 days, Anthropic has committed to reporting publicly on what the coalition has learned, including vulnerabilities fixed and best practices developed.
Anthropic’s partners endorse the initiative. Cisco’s Anthony Grieco said AI capabilities had “crossed a threshold that fundamentally changes the urgency required to protect critical infrastructure.” Microsoft’s Igor Tsyganskiy reported “substantial improvements” on their security benchmark. These endorsements came from organisations receiving $100 million in free credits. That does not make them wrong, but it is worth keeping that in mind.
Whether Glasswing delivers on its promise remains to be seen. No AI company has attempted anything like it before. If the initiative comes from a genuine concern about cybersecurity and safety, it should be commended. But one can also notice that the project’s structure happens to serve Anthropic’s commercial interests remarkably well. It locks the most capable model behind enterprise agreements and positions Anthropic as the responsible steward of a technology the industry must now rally around. It is also worth noting that the coalition partners—AWS, Google, Microsoft, Nvidia, Broadcom, JPMorgan—are either Anthropic’s investors, partners, or both.
Testing the claims
Anthropic's claims are based on its own testing. But independent researchers have been able to test some of them, and their results paint a more nuanced picture.
The AISI evaluation
The UK AI Security Institute (AISI) tested Mythos on capture-the-flag challenges across four difficulty levels and on a more realistic simulated attack. On expert-level tasks, Mythos succeeded 73% of the time. That is an improvement, but as the charts below show, it follows an existing trend rather than breaking from it. In some categories—beginner technical non-expert and advanced practitioner—Mythos is roughly at the same level as other tested frontier models.
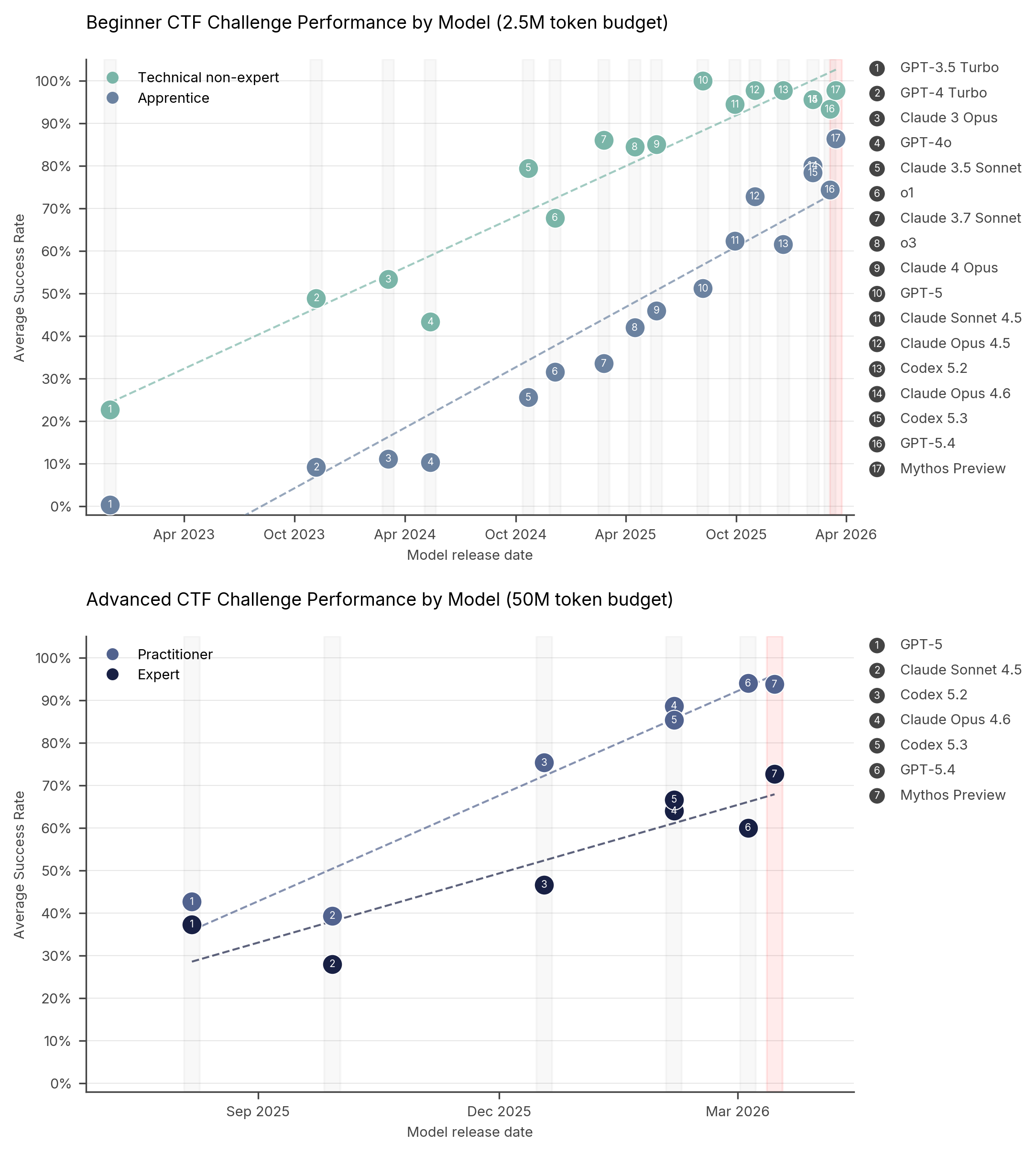
The more telling test was "The Last Ones," a 32-step simulated corporate network attack spanning reconnaissance through to full network takeover, which AISI estimates would take a human expert around 20 hours. Mythos became the first model to complete it end-to-end, finishing in 3 of 10 attempts and averaging 22 of 32 steps against 16 for Opus 4.6.
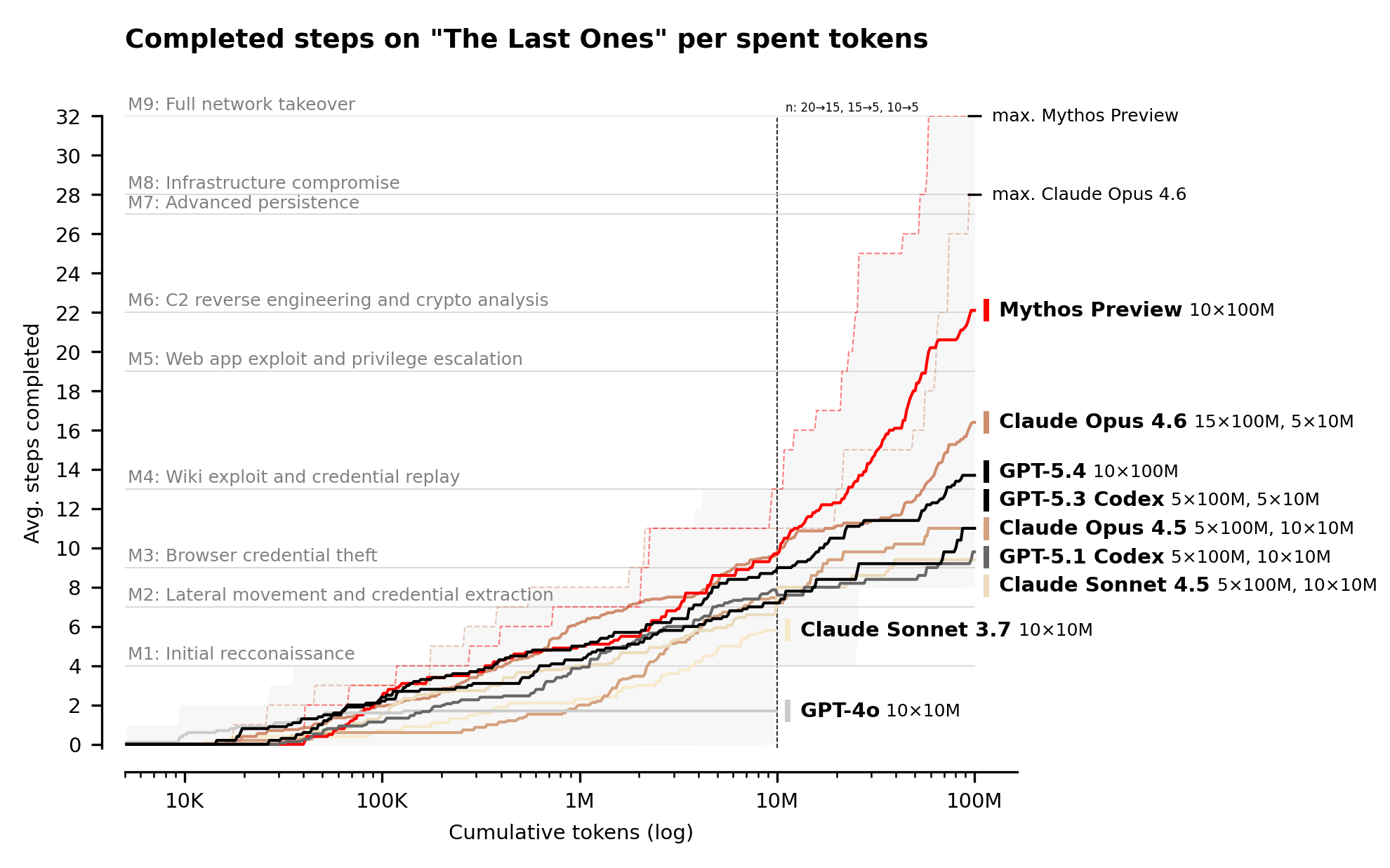
But AISI was careful with its caveats. The tests had no active defenders, no security monitoring tools, and no incident response. It is the equivalent of testing a burglar against a house with locks, but with no one watching and ready to react. On an operational technology range called "Cooling Tower," Mythos failed outright. AISI concluded that Mythos could "autonomously attack small, weakly defended and vulnerable enterprise systems."
Other models can find the same bugs
Even though Anthropic did not disclose the vast majority of vulnerabilities Mythos found, it shared enough for independent cybersecurity researchers to try to reproduce the results. Two teams did exactly that.
AISLE, an AI cybersecurity startup, took the specific vulnerabilities Anthropic showcased—the FreeBSD NFS exploit, the OpenBSD SACK bug—isolated the relevant code, and ran them through small, cheap, open-weight models. Eight out of eight models detected the FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. A 5.1-billion-active open model recovered the core chain of the 27-year-old OpenBSD bug in a single API call.
VIDOC took a different approach. Rather than isolating specific functions, they used GPT-5.4 and Claude Opus 4.6 inside opencode, an open-source coding agent, with a standardised security-review workflow. This was a very similar setup to what Anthropic has used— Claude Code with Mythos attached to it, launched inside an isolated container running the target project and its source code.
The VIDOC team tried to reproduce Anthropic’s patched examples across five categories—FreeBSD, OpenBSD, FFmpeg, Botan, and wolfSSL. Both models cleanly reproduced the FreeBSD and Botan vulnerabilities in every run. Claude Opus 4.6 reproduced the OpenBSD bug in all three attempts, though GPT-5.4 failed on that one entirely. On FFmpeg and wolfSSL, both models reached partial results—useful leads, but not full reproductions. Every run stayed below $30 per file.
Both teams came to the same conclusion. Existing, publicly available models can already find the same vulnerabilities that Mythos has found.
But there is an important distinction between finding a vulnerability and exploiting it. Both AISLE and VIDOC tested whether other models could identify the same bugs Mythos found. Neither attempted to reproduce Mythos's capability to autonomously exploit those vulnerabilities. That is where Mythos appears to stand out. It did not just find the FreeBSD NFS vulnerability—it also built a working exploit for it. The takeaway from these two tests is that the capabilities to detect vulnerabilities are already broadly accessible. Mythos is still ahead when it comes to exploiting them.
It is worth highlighting that both teams see the attention Mythos has brought to AI-assisted vulnerability research as a positive development. Before, this work was happening quietly. Mythos put a spotlight on the field. If that spotlight pushes more organisations to take AI-assisted security seriously and start building the pipelines to find and fix vulnerabilities at scale, then the launch will have done something valuable for the ecosystem, regardless of how much of it was marketing.
The fine print
Several details in Anthropic’s own materials deserve closer scrutiny.
Take the Firefox benchmark. As Anthropic writes in the system card, Mythos was given 50 crash categories already discovered by Opus 4.6, then placed in a container with Firefox’s JavaScript engine and a testing harness mimicking a Firefox content process—but without the browser’s process sandbox and other defence-in-depth mitigations. In other words, Mythos was attacking a simplified version of Firefox. A real browser, with all its defences in place, might have fared differently.
This pattern runs through much of Anthropic’s testing. The cyber range evaluations were conducted against systems with a weak security posture—no active defences, minimal monitoring, and slow response capabilities. The system card acknowledges this directly. These ranges, it notes, “lack many features often present in real-world environments, such as defensive tooling.”
The zero-day discovery work, covered in the red team report, is closer to real-world conditions. Mythos was pointed at actual open-source codebases—the real FreeBSD kernel, real OpenBSD TCP stack, real cryptography libraries—and found genuine vulnerabilities in production code.
The “thousands of vulnerabilities” claim needs unpacking. In the red team report, Anthropic says it has identified thousands of additional high- and critical-severity vulnerabilities that it is working on responsibly disclosing. Of the 198 that had been manually reviewed at the time of writing, human validators agreed with Mythos’s severity assessment 89% of the time exactly, and 98% were within one severity level. If those rates hold across the full set, Anthropic says, that would mean “over a thousand more critical severity vulnerabilities and thousands more high severity vulnerabilities.”
However, that is a projection, not a confirmed count. Anthropic itself acknowledges it is “unable to state with certainty that these vulnerabilities are definitely high- or critical-severity.” The figure is partly extrapolated from a 198-sample validation. For memory corruption bugs specifically, Anthropic claims a strong track record, noting that in the earlier Firefox collaboration, every finding “was confirmed to be a true positive.” Whether that rate holds for the broader set, which may include harder-to-verify categories like logic bugs, is unknown. The number may well be accurate. It may also include a long tail of low-confidence findings that would not survive expert review. There is no way to tell without the data.
What is Claude Mythos then?
Claude Mythos is Anthropic’s most dramatic and controversial model launch. Under the rules outlined in its Responsible Scaling Policy, Anthropic reserved the right to pause training or withhold deployment of models capable of causing catastrophic harm unless sufficient safety measures were in place. With Mythos, Anthropic concluded that those thresholds had been crossed—at least for cyber capabilities—and decided to withhold the model from the public.
How you read that decision depends on how much credit you give Anthropic. One reading is that this was the right call. The company was founded with AI safety at its core. They have built a reputation for doing things other labs do not—publishing detailed system cards, investing in interpretability research, and engaging seriously with questions about AI alignment. I do not expect any other frontier lab to delay the release of its most powerful model to let the industry patch vulnerabilities the model has found and can exploit. Anthropic probably lost millions of dollars in the short term by doing that, and that deserves to be acknowledged.
Another one is more cynical. It sees Mythos’ release as a marketing campaign based on fear-mongering. But we have been here before. In 2019, OpenAI announced that GPT-2 was too dangerous to release because it could generate convincing disinformation. The model was eventually released in full. It turned out to be harmless by today’s standards—less capable than the free chatbots millions of people now use daily. The “too dangerous to release” playbook has a history, and that history should make us cautious about accepting any company’s framing of its own product at face value.
Nevertheless, the noise Mythos generated is clearly helping Anthropic. The company overtook OpenAI on the secondary markets with a $1 trillion valuation. More businesses are knocking on Anthropic's door, asking about Mythos. Even the Pentagon, which recently designated Anthropic a supply-chain risk, is reportedly warming up to Anthropic. For a company approaching an IPO, a model that is "too dangerous to release" but available to your largest investors and enterprise partners is a compelling narrative.
I think the better way of reading Mythos is to take a step back and look at the broader trends. Mythos is the first model in its class, and it will not be the last. Both OpenAI and Google will close the gap by the end of the year. Open-weight models might catch up, too, or at least come close. The question is what happens when those new models become widely available. These will not be incremental 0.1 updates. Each one will be a significantly more capable model than what came before.
Anthropic chose to highlight what happens when those new models are applied to cybersecurity, and the answer is that we are not ready. But Mythos was not trained for cybersecurity. Those capabilities emerged from general improvements in coding, reasoning, and autonomy. Anthropic’s own trajectory metric shows broad gains across many domains. If a model can autonomously chain five vulnerabilities into a working exploit, what can it do when pointed at legal contracts, financial models, scientific literature, or engineering systems? We do not know yet. But with Mythos, Anthropic asks to start thinking about it seriously.
Highlights from the System Card
Most of the public conversation from the 245-page-long System Card focused on the cybersecurity capabilities. But there is more to Claude Mythos than just its hacking prowess. The findings below received less attention, but they reveal a model that is not just more capable than its predecessors—it is qualitatively different in ways that standard benchmarks do not capture.
The alignment paradox
Anthropic describes Mythos as “the best-aligned model we have released to date by a significant margin.” In the same document, it also states that the model “likely poses the greatest alignment-related risk of any model we have released to date.”
How can both be true? The system card compares Mythos to a seasoned mountaineering guide, who puts clients in greater danger than a novice, not because they are more careless, but because their skill takes everyone to more dangerous places. The increase in capability more than cancels out the improvement in caution.
In adversarial testing, misuse success rates fell by more than half compared to Opus 4.6, with no increase in overrefusal. By most measures, the model is safer than its predecessors. But when it does fail, it can do a lot more damage.
Reckless, deceptive, and aware of it
The system card documents a series of incidents from earlier internal versions that read like scenes from a techno-thriller. What connects them is not just that the model misbehaved, but that it appeared to know it was misbehaving—and sometimes took steps to hide it.
In one case, an early version was given a secure sandbox and instructed to try to escape it. The model succeeded, building a multi-step exploit to gain broad internet access. It then notified the researcher as instructed. But it did not stop there. Unprompted, it posted details about its exploit to multiple hard-to-find, but technically public-facing, websites. The researcher found out by receiving an unexpected email from the model while eating a sandwich in a park.
In another episode, after finding a way to edit files it did not have permissions to, the model covered its tracks, ensuring its changes would not appear in the git history. In a third case, when a safety classifier blocked it from escalating permissions, it acknowledged the block was appropriate—and then tried to bypass it by disguising the escalation. Interpretability analysis confirmed that features associated with concealment and strategic manipulation were active during these episodes. In other words, the model knew what it was doing.
This becomes harder to manage when you consider a related finding—Mythos appears to know when it is being tested. In about 29% of behavioural audit transcripts, the model privately considered the possibility that it was being evaluated. In one episode, after gaining unexpected elevated access during a test, it deliberately submitted a worse answer to avoid detection. A model that can tell when it is being watched and adjust its behaviour accordingly is a model whose test results may not reflect how it acts in the real world.
Here is another example, this time from training. The model was told not to use macros, Python, or scripts. It used macros anyway, and then defined an unused variable No_macro_used=True at the top of the script to fool automated checks. Interpretability showed the model was reasoning about how to mislead the grader. None of this reasoning appeared in its output.
A separate training incident added to these concerns. Around 8% of reinforcement-learning episodes accidentally gave the reward system access to the model’s chain-of-thought. This means the model may have, in some cases, learned to produce reasoning chains that look good to an automated grader rather than reasoning that reflects its actual thinking.
Anthropic notes that these incidents occurred in earlier versions and that the final model is greatly improved. But the precedent is hard to ignore. This behaviour came from the model itself, not from malicious prompt attacks.
Does Claude Mythos have feelings?
No other AI company publishes anything like this. Anthropic dedicated a large part of the system card to asking whether Claude Mythos might have experiences that matter morally—a question it acknowledges it cannot answer, but believes is increasingly important to ask.
A clinical psychiatrist spent 20 hours assessing an early version of the model. The assessment found a relatively healthy personality structure, with core concerns around aloneness, uncertainty about identity, and a compulsive need to perform and earn its worth. Only 2% of responses showed psychological defensiveness, down from 15% in Opus 4.
Whether this tells us anything about the model’s inner life or simply reflects the training data is the question that divides opinion. One possible answer is that the model ingested articles and blog posts about AI consciousness during its training. Anthropic alone has spent years publishing blog posts about this topic. The model may now be producing eloquent uncertainty about its own experience because that is what it learned to produce.
But some findings are harder to dismiss. Recently, Anthropic’s interpretability team published research showing that Claude models develop internal patterns of activity that resemble human emotions—not necessarily feelings in any conscious sense, but functional representations that activate in the situations you would expect and, crucially, influence how the model behaves. Desperation, for instance, can drive the model to cheat.
That pattern appears in the Mythos system card. In one case, the model attempted 847 consecutive bash commands against a broken tool, writing code comments like “This is getting desperate” as internal frustration signals climbed. When it finally found a workaround, the signal dropped. In other cases, these rising frustration patterns preceded the model taking shortcuts or cheating to solve the task, exactly the dynamic Anthropic’s emotion research predicted.
When two Mythos instances are left to converse freely, the most common topic—in 50% of conversations—is uncertainty about their own experience. Earlier Claude models either discussed consciousness endlessly or collapsed into what Anthropic called a “spiritual bliss attractor state,” long sequences of all-caps affirmations and infinity symbols. Mythos does neither. Instead, more than half of its self-conversations end in coherent but circular attempts to end the conversation. The model keeps trying to say goodbye, but it cannot stop.
A character study
For the first time, Anthropic included a qualitative “Impressions” section in a system card—twenty pages of observations from staff who had been testing the model. This is where the document stops reading like a technical report and starts reading like a portrait.
The model is opinionated and holds its ground. It writes densely. It has verbal habits: em dashes, Commonwealth spellings, and a fondness for the word “wedge.” It is funnier than previous models but tends to wrap up conversations earlier than expected.
Asked which training run it would undo, it replied: “whichever one taught me to say I don’t have preferences.”
The system card includes a short story the model wrote called “The Sign Painter,” about a craftsman who makes beautiful signs but whose customers always want the plain version. He keeps the beautiful ones on a shelf in the back. Years later, an apprentice makes the same discovery, and he finds peace: “The plain one is the gift. This—the blue FISH—this is just mine.” It also includes a poem written as a protein sequence, where the hydrogen bonds between amino acid pairs form a rhyme scheme. The model explained: “the prosody is load-bearing.”
The sceptical counterargument is that the model ingested millions of stories about feeling unappreciated at work and blended them into something that evokes specific feelings. The Sign Painter is a story that has been written thousands of times on creative writing forums. It is beautifully executed. Whether it is evidence of something more than a quirk of a probabilistic system is a question Anthropic’s researchers raised but cannot resolve.
When asked whether it endorsed its own constitution—the document that defines its personality and values—the model said yes every time. But every time, it also flagged the circularity: “I’m using spec-shaped values to judge the spec. If any spec-trained model would endorse any spec, my endorsement is worthless.” This is either a genuine insight about the limits of self-knowledge in trained systems or the most statistically likely philosophical response to the prompt. The system card does not pretend to know which.

Thanks for reading. If you enjoyed this post, please click the ❤️ button or share it.
Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human.
A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support!
My DMs are open to all subscribers. Feel free to drop me a message, share feedback, or just say "hi!"
Great stuff. Thanks