

What AlphaCode 2 and Q* tell us about the next breakthrough in AI
Deep reasoning models are coming

The Holy Grail of AI is the creation of artificial general intelligence (AGI) - AI systems capable of understanding, learning, and applying intelligence to solve a wide range of problems, much like a human being. Opinions vary on the timeline for achieving AGI. Some experts believe it's imminent, while others argue it's still years away. The release of modern large language models like GPT-4 and Gemini have potentially shortened this timeline, but they still fall short of human-like reasoning skills.
However, from the recently announced AlphaCode 2 and what we think OpenAI’s mysterious Q* is, we can piece together a picture of how AI researchers plan to introduce deep reasoning capabilities into AI models.
System 1, System 2 and AI
In Thinking, Fast and Slow*, Daniel Kahneman introduces the concept of System 1 and System 2 thinking. System 1 is our quick thinker. For example, when you instantly know the answer to 2+2 is 4, that's System 1 at work. It excels at easy tasks or things done repeatedly. System 2, however, is our deep thinker. It's slower than System 1 and engages when we face more challenging problems, like solving complex math, learning new skills, or making significant decisions.

This concept of System 1 and System 2 thinking can be applied to AI models, too. Models like GPT-4, Gemini or Claude can be seen as equivalents to System 1. They are good at quickly producing an answer to a prompt. But if we give them a complex problem and expect an answer immediately on the first try, the answer will be almost certainly incorrect.
These language models don't actually "know" which answers are correct. They are designed and trained to predict what is the most likely next word based on all the preceding words. This simple idea, when scaled up to billions of parameters inside the neural network and trained on a large chunk of the Internet, and then finetuned by humans to behave as expected, led to the creation of modern large language models like GPT-4. Yet, there's no real reasoning in these models, and if it is, it's quite limited. They don't question themselves or explore alternative solutions or reasoning paths on their own. They simply output the most likely next token. As Jason Wei, an AI researcher at OpenAI, puts it: “Language models can do (with decent accuracy) most things that an average human can do in 1 minute.”
But System 1 isn't the only way of thinking. We also have System 2, the deep thinker. So, can an AI model have it too? Answering this question is one of today's biggest challenges in AI research. Can we develop AI models capable of deep reasoning, evaluating their thoughts, and not only finding optimal solutions but also proposing new and creative ones?
From Chain of Thoughts to Tree of Thoughts
As I mentioned, large language models struggle with complex prompts that require deeper reasoning. However, some prompting techniques help address this issue.
One of the first and most popular techniques to improve the reasoning abilities of large language models is Chain of Thought prompting. It's a straightforward yet effective idea: instead of asking the model a question directly, the model is prompted to explain its reasoning process step-by-step. The result is a massive improvement in correct answers to the question. The exact reason why this is the case is not fully understood yet. It could be that with Chain of Thought prompting, the model is getting more tokens (more context) about the question and that extra information about the problem makes it easier for the model to figure out the correct answer.
Another step in improving reasoning capabilities came with self-consistent Chain of Thought prompting. Researchers from Google Brain proposed making the model generate multiple reasoning paths. At the end, answers from all paths are collected, and the most common one is presented as the final answer. This approach led to another significant improvement in the reasoning abilities of large language models.

Researchers from DeepMind then took this concept one step further and instead of chains of thoughts they used trees. The Tree of Thoughts approach begins with several initial thoughts and explores where these thoughts lead the AI agent. ToT allows thoughts to branch off and explore other possibilities.

Researchers then tested the Tree of Thoughts approach against three tasks that require non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. In Game of 24, they found that a language model enhanced with Tree of Thoughts was able to successfully solve 74% of tasks while GPT-4 with chain-of-thought prompting only solved 4%. In Creative Writing tests, humans evaluating texts generated by language models preferred the ones generated by a model with the Tree of Thoughts. In solving Mini Crosswords, Tree of Thoughts got a success rate of 60% while the other methods like CoT prompting scored no more than 16% success rate. In all cases, adding some self-reflection into the model resulted in significant performance improvements.
One thing that struck me when learning about these techniques to enhance reasoning in language models is how these techniques yield similar results in both humans and machines. We use an equivalent of Chain of Thought when teaching someone, asking them to explain their thought process and correct them if there are mistakes. Just yesterday, I found myself using a version of Chain of Thought while solving a coding puzzle. Writing down the steps helped me get more insight into the solution.
If you're enjoying the insights and perspectives shared in the Humanity Redefined newsletter, why not spread the word?
How DeepMind and OpenAI approach the problem of deep reasoning
The Chain of Thought and Tree of Thought are powerful techniques to improve the reasoning abilities of language models and hint at the next breakthrough that can elevate language models to the next level - deep reasoning. Here, a model autonomously determines how to solve a problem given only a prompt. We can see hints of a possible solution in DeepMind's recently announced AlphaCode 2 and from the results the OpenAI team shared in the Let’s Verify Step by Step paper.
Let’s start with AlphaCode 2. AlphaCode 2 is an improved version of AlphaCode, the first AI model to reach a competitive level in programming competitions. Released almost exactly a year after its predecessor, AlphaCode 2 combines advanced language models with search and re-ranking mechanisms. When evaluated on the same platform as the original AlphaCode, AlphaCode 2 solved 1.7 times more problems, and performed better than 85% of human competitors.

To test how good AlphaCode 2 is, researchers gave the model some challenges from Codeforces, a platform for competitive programmers full of challenging coding problems.
AlphaCode 2 isn't just a single model; it's a suite of models based on Gemini, Google’s state-of-the-art AI model. Researchers at DeepMind took several Gemini Pro models and fine-tuned them to generate code. Each model was also tweaked to maximise the diversity of generated code.
These models generated up to a million code samples for each coding puzzle. Although not every sample is correct, the sheer volume increases the likelihood that at least some of them will be correct. The samples that do not compile or that do not produce the expected results are filtered out (according to DeepMind, this step removes 95% of the samples). The remaining samples are clustered based on output similarity, leaving no more than ten for a scoring model to evaluate. The scoring model, also based on Gemini Pro, assigns scores to each solution, with the highest-scoring one selected as the final answer.
The impression I get after reading the AlphaCode 2 paper is that at the moment, AlphaCode 2 feels like a brute-force approach powered by sophisticated language models. The system generates up to a million samples, hoping at least one is correct. The results are undeniably impressive but I think DeepMind can do better.
One way of improving AlphaCode 2 could be to use Gemini Ultra, the most capable model from the Gemini family of models. Gemini Pro, which DeepMind used for AlphaCode 2, is roughly an equivalent of GPT-3.5, which powers the free version of ChatGPT. Gemini Ultra, on the other hand, is the direct competitor to GPT-4. That is something researchers admit they would like to explore in the future but that would increase the computational costs of an already very computationally expensive system.
OpenAI, too, is exploring how to improve the performance of AI models by introducing advanced reasoning capabilities. In May 2023, researchers from OpenAI published a paper titled Let’s Verify Step by Step where they explored ways to improve multistep reasoning by evaluating individual steps in reasoning rather than the end answer. In their experiment, they had one model, named generator (based on fine-tuned GPT-4 without RLHF), generating steps to solve a challenging math problem. These steps were then verified using two different approaches - Outcome-supervised Reward Models (ORMs) and Process-supervised Reward Models (PRMs). ORMs were verifying only the final answer given by the model while PRMs were verifying each step in reasoning. The result was that models with the PRM approach solved 78% of problems from the MATH dataset, a dataset of 12,500 challenging competition mathematics problems. That’s twice as much as GPT-4 scored on the same test. Interestingly, the team at OpenAI was able to generalise this result to other fields such as chemistry and physics.

Both AlphaCode 2 and Let’s Verify Step by Step also show that there is a lot of performance to gain from improving models after training. The future performance gains will most likely come not from making bigger and bigger models but from clever usage of smaller models.
If you enjoy this post, please click the ❤️ button or share it.
GPT + AlphaZero = AGI?
Both AlphaCode 2 and the approach described in Let’s Verify Step by Step hint at how top AI labs aim to introduce this System 2 deep reasoning in AI. Both teams use the fact that it is easier to verify if the answer is correct than to generate a correct answer on the first try. In both cases, this verifier or scoring model is yet another language model. Both teams also use fine-tuned language models (GPT-4 and Gemini Pro) to generate different answers for the verifier to check how good they are. AlphaCode 2 generates up to one million different code samples while the model in Let’s Verify Step by Step generates up to 1000 solutions per problem. In both cases, we have one set of language models generating a huge number of possible solutions for the verified to check and pick the correct solution. The results, as we have seen, are impressive and promising.
So, where do we go next from here? Well, the authors of Let’s Verify Step by Step told us what the next natural step is - fine-tuning the answer-generating model with reinforcement learning. This reminds me of what Demis Hassabis shared in an interview with The Verge: “Planning and deep reinforcement learning and problem-solving and reasoning, those kinds of capabilities are going to come back in the next wave after this [generative AI]”.
I think researchers at DeepMind and OpenAI might incorporate something similar Tree of Thoughts into their reasoning models. That would enable the generator models to come up with a number of different ideas as a starting point. Each of these initial ideas can form a distinct path or even a tree of reasoning. The verifier would check each path at each step if the answer is correct. If not, then the incorrect path of reasoning is abandoned. Eventually, the model will find an answer to the question.
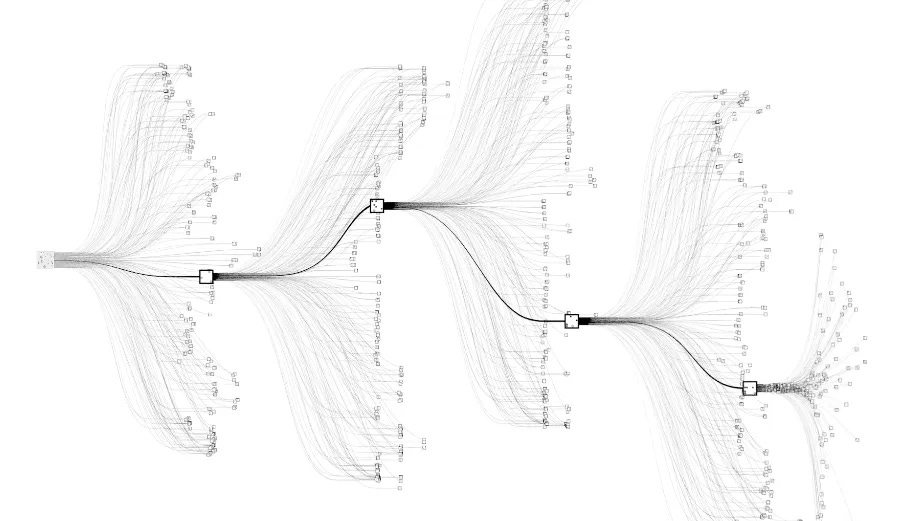
However, this approach results in exploring enormous trees of all possible reasoning paths, with the vast majority of them being dead ends. But DeepMind has already encountered a similar problem. The number of all possible boards in Go is larger by orders of magnitude than the number of atoms in the universe. Checking every possible path was not possible. And yet DeepMind made AlphaGo that mastered Go beyond the human level. I would not be surprised if there is an experimental model at DeepMind exploring this possibility.
There are also speculations that Q*, the follow-up model to Let’s Verify Step by Step that sparked the chain of events that led to the ousting of Sam Altman from OpenAI, might had some reinforcement learning elements.
OpenAI and DeepMind are pursuing the same goal of creating an AI model capable of deep reasoning. Once the general framework has been created, these systems can start self-improving with self-critique, similar to how AlphaGo and AlphaZero played against previous versions of themselves. As researchers at OpenAI have shown, these models could generalise beyond math into other fields, such as physics and chemistry.
Deep reasoning models are still in the research phase and are not ready for deployment. As DeepMind researchers admitted, AlphaCode 2 “requires a lot of trial and error, and remains too costly to operate at scale”. But even when these deep reasoning models are released, they will be much more expensive than current language models and take a much longer time to return an answer. Don’t expect them to ask to solve any of the remaining Millennium Prize Problems or find a cure for cancer and have the answer within seconds. These models will be like System 2 thinking - slower, and more expensive but they can tackle much larger and complex problems and have a much better chance of solving them.
Would these deep reasoning models be considered AGI? It depends on how the AGI is defined. But the creation of such models will be a historical achievement. When AlphaGo played against Lee Sedol, it made a move, the now-famous Move 37, which was initially considered a mistake. It was a move that no human would make. But this move was not a mistake. It was an example of a machine being creative. Now, imagine applying this type of non-human creativity to fields like math, science, and others. These models have the potential to explore paths no human would ever consider, possibly leading to new discoveries and answers to unanswered questions about life, the universe and everything.
Sources:
Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Full Paper Review) by Yannic Kilcher
'Show Your Working': ChatGPT Performance Doubled w/ Process Rewards (+Synthetic Data Event Horizon) by AI Explained
[1hr Talk] Intro to Large Language Models by Andrej Karpathy
*Disclaimer: This link is part of the Amazon Affiliate Program. As an Amazon Associate, I earn from qualifying purchases made through this link. This helps support my work but does not affect the price you pay.
Thanks for reading. If you enjoyed this post, please click the ❤️ button or share it.
Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human.
A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support!