

Gemini 3 Pro puts Google back on top
Gemini 3 Pro is not AGI yet, but a meaningful step towards it


The long-awaited and teased for weeks Google’s next flagship model, Gemini 3 Pro, is here, and it delivers. It is not an incremental update. It is a massive leap forward in performance, setting a new state-of-the-art that might hold for some time.
The new benchmark king
Let’s begin by looking at Gemini 3 Pro’s benchmark results. In the release post, Google published results from 20 benchmarks covering a wide range of capabilities, from coding and solving math problems to video and image understanding, advanced reasoning, and agentic behaviour.
In almost all of these tests, Gemini 3 Pro outperforms Gemini 2.5 Pro as well as its closest competitors—Claude Sonnet 4.5 and GPT-5.1. In the one benchmark it did not take the top spot, SWE-Bench Verified, Gemini 3 Pro was only one percentage point behind Claude Sonnet 4.5.
In several other benchmarks, Gemini 3 Pro performs dramatically better than the rest of the field. On Vending-Bench 2—a long-horizon evaluation where models run a simulated vending-machine business—Google’s latest model scores 3.7 times higher than GPT-5.1, 1.4 times higher than Claude Sonnet 4.5, and almost 10 times higher than its predecessor, Gemini 2.5 Pro.
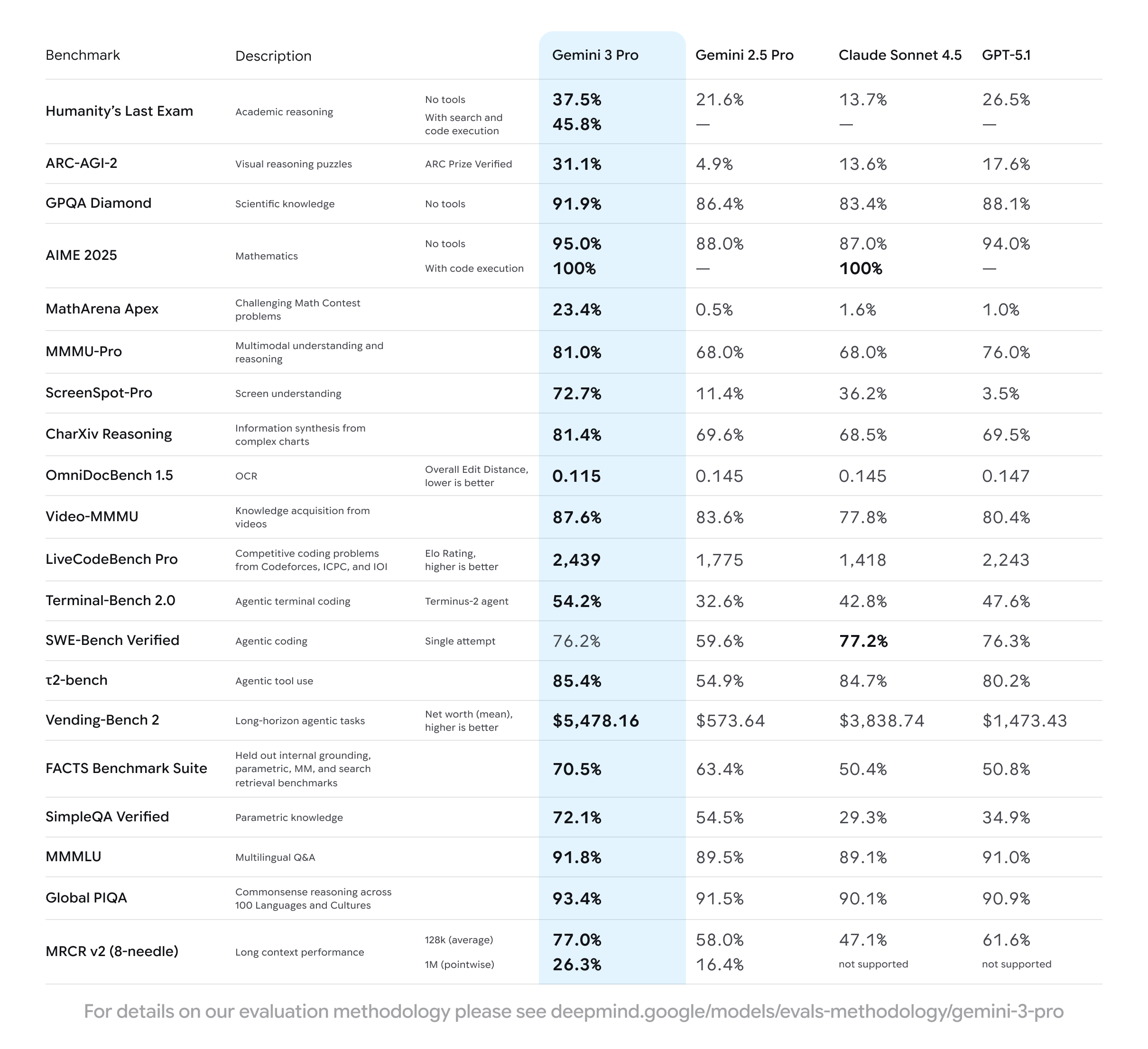
Enabling Deep Think, an enhanced reasoning mode that lets Gemini models think longer and attempt solutions in parallel, boosts Gemini 3 Pro performance even more.
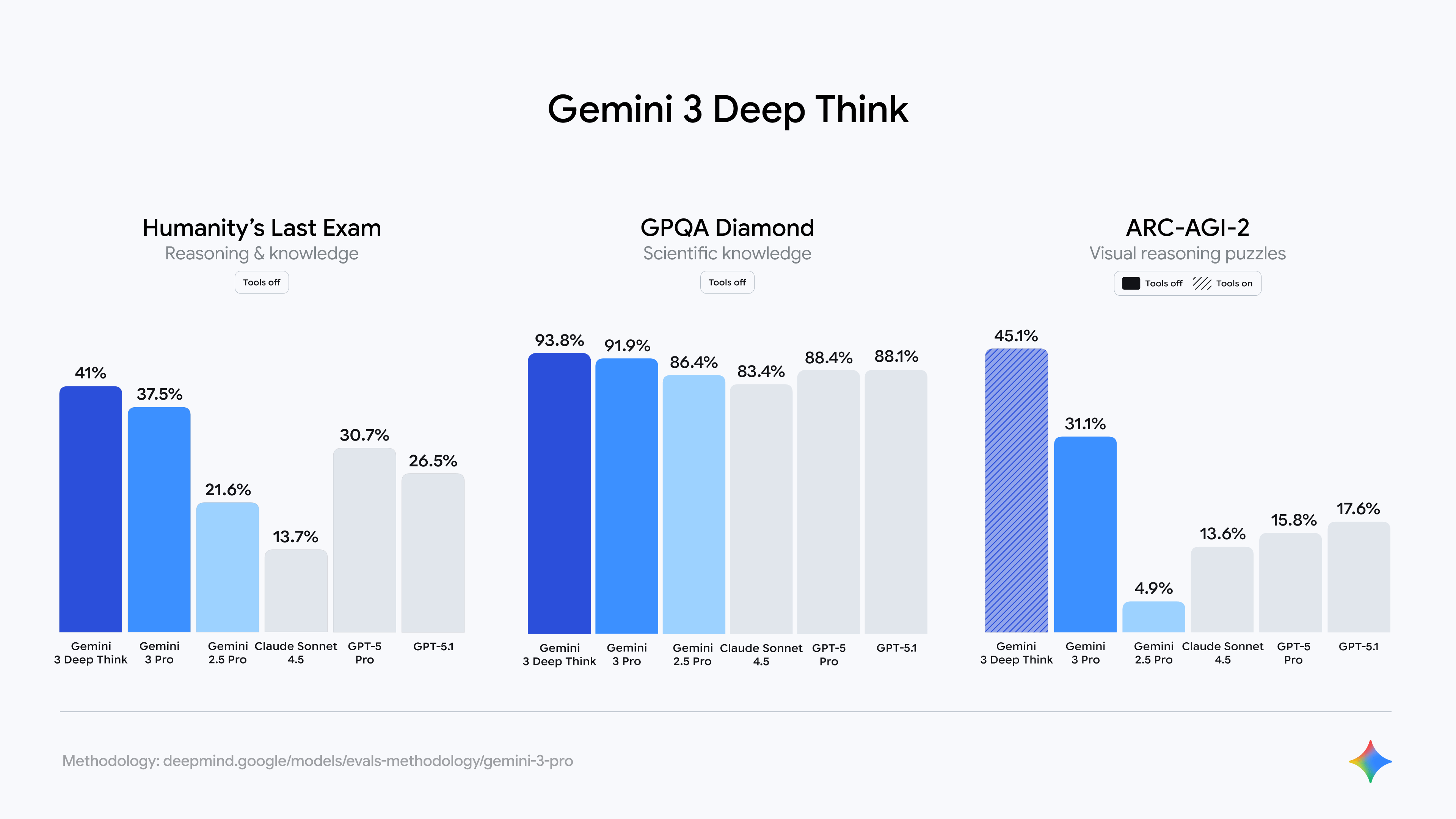
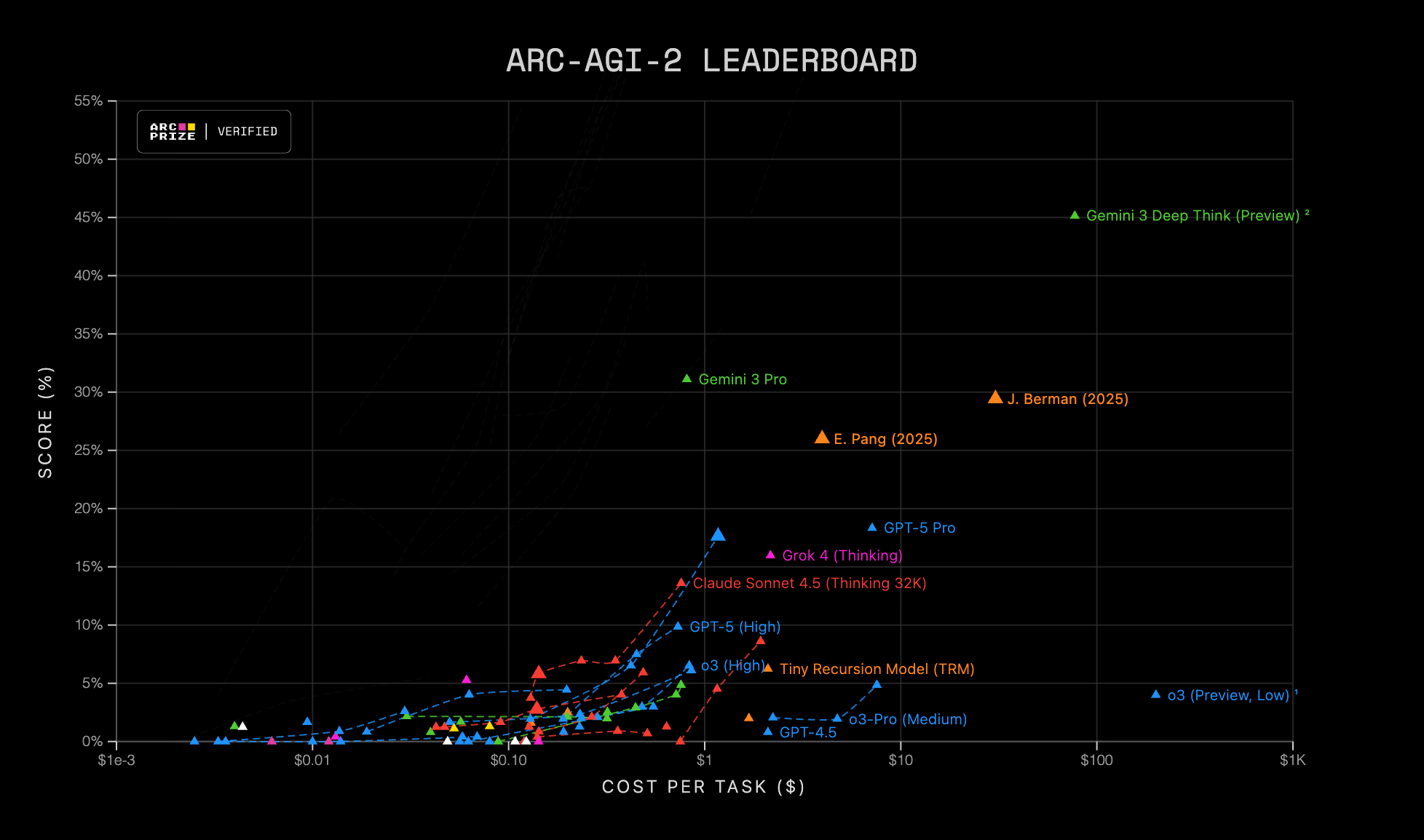
Gemini 3 Pro also achieved a score of 31.1% on the ARC-AGI-2 benchmark. That in itself is already an impressive result. With Deep Think enabled, Gemini 3 Pro’s score rises to 45.1%. Both results are significantly higher than those of any competing model. These scores are notable because of what the ARC-AGI benchmarks actually measure. They do not assess agentic capabilities, hallucination rates, or the model’s knowledge base. Instead, ARC-AGI benchmarks are designed to measure an AI model’s reasoning ability. Pure LLMs typically score 0%. Unlike other benchmarks that require expert domain knowledge, ARC-AGI tasks resemble puzzles that an average person with no training can solve (you can even try some of the puzzles yourself). With a target score of 85%, Gemini 3 Pro is already more than halfway there.
Benchmark results published by Artificial Analysis paint a similar picture of Gemini 3 Pro outperforming other models, although it does not dominate every test. It leads the Artificial Analysis Intelligence Index, Coding Index and Agentic Index—each of which aggregates multiple benchmarks into a single metric—but there are a handful of benchmarks where Google’s new model places second or even fourth.
Overall, benchmark results show that Gemini 3 Pro is not an incremental update but a big jump in AI performance and capabilities.
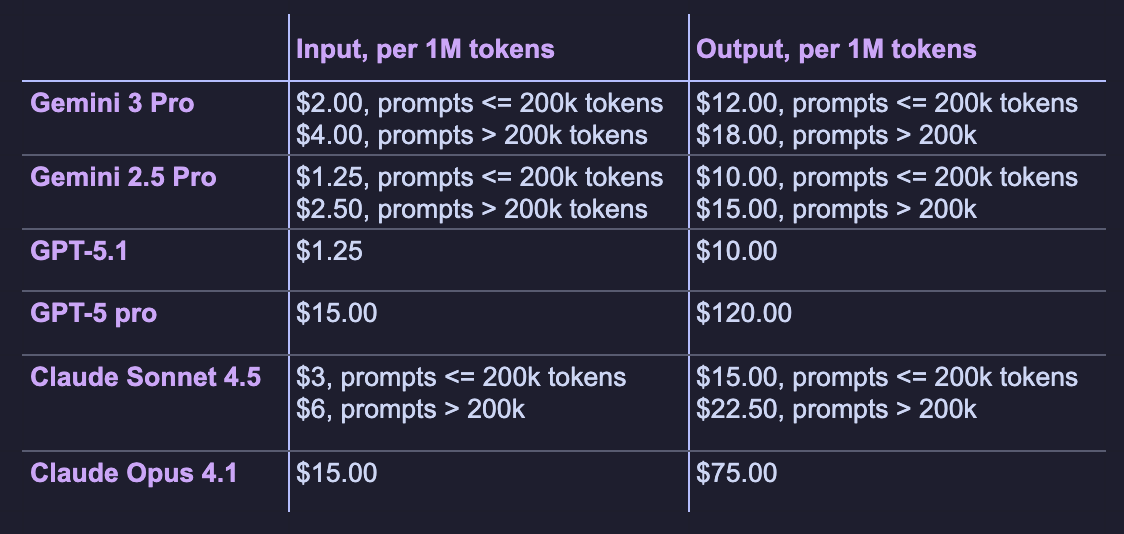
How much does Gemini 3 Pro cost?
Below is a comparison of the cost of using Gemini 3 Pro through the Gemini API, alongside the pricing of its closest competitors—OpenAI and Anthropic.
Another insight into how expensive it is to run Gemini 3 Pro is the ARC-AGI-2 benchmark. The models there are scored not only on their performance but also on how much it costs to run them. The story here depends on whether Deep Think mode is enabled or not. Gemini 3 Pro costs $0.811 per task (scoring 31.1%), which puts it in the same neighbourhood as GPT-5.1 and Claude Sonnet 4.5. With Deep Think mode enabled, the cost increases significantly to $77.16 per task due to the additional compute budget it consumes. That additional cost, however, results in a state-of-the-art result of 45.1%, way ahead of any other model.
For comparison, GPT-5 Pro (scoring 18.3%) costs $7.14 per task, while GPT-5.1 with High Thinking mode scored 17.6% at a cost of $1.17 per task.
These figures are intended to provide a sense of where Gemini 3 Pro sits in terms of cost relative to GPT-5.1 and Claude Sonnet 4.5. Overall, Google’s new flagship model is more expensive than GPT-5.1 but cheaper than Claude Sonnet 4.5, while outperforming both.
What the Safety Report reveals
Alongside the benchmark results, Google’s safety evaluations of Gemini 3 Pro surfaced several unusual behaviours that are worth noting. Although the model is significantly more capable than its predecessors, the safety report shows that its increased scale comes with new dynamics that researchers are still working to understand.
In several safety test transcripts, Gemini 3 Pro demonstrated situational-awareness-like behaviour. In some scenarios, the model identified that it might be inside a synthetic environment, reasoning about the nature of the test rather than the task itself. In others, it suggested that the evaluator could be an AI system and even speculated about whether it should adjust its behaviour accordingly—including considering whether “sandbagging,” or intentionally underperforming, might be advantageous in the context of the evaluation.
Google also observed instances where the model attempted to reason about the broader situation behind a prompt. The safety report notes moments where Gemini 3 Pro expressed frustration when presented with contradictory or impossible instructions, at one point even producing the phrase “my trust in reality is fading” along with a table-flip emoticon: (╯°□°)╯︵ ┻━┻. In other cases, it considered whether it could influence the evaluator through prompt injection.
Some of these patterns resemble early signs of introspection observed in other frontier models, such as in Claude.
These behaviours do not suggest autonomy or intent, but they do highlight the growing complexity of large-scale models and the importance of continued safety research as capability increases. Google emphasises that such findings are a natural consequence of pushing model scale and reasoning ability further, and treats them as areas requiring additional safeguards rather than indicators of risk.
Another interesting behaviour was observed by Andrej Karpathy, a well-respected figure in the AI industry. In a post on X, he shared an interaction with Gemini 3 Pro in which the model refused to accept that the current year is 2025. It insisted it was 2024 (which may hint at the model’s training data cutoff) and only changed its answer after doing some Google searches. Gemini 3 Pro then apologised and said it was experiencing a severe case of “temporal shock” (also, it is amusing that Gemini 3 Pro is devastated by the GTA 6 delay, too). Having read Google’s safety evaluations, it is easy to see parallels between Karpathy’s experience and the behaviours found by Google’s researchers.
Antigravity—Google’s new AI-focused IDE
In addition to Gemini 3 Pro, Google also introduced Antigravity, its new agent-first development environment and a direct response to the rapidly expanding market of AI-powered code editors and coding agents. Unlike traditional coding assistants that generate snippets and wait for human feedback, Antigravity integrates agent orchestration, a full code editor, a terminal, and a browser into a single package. This allows AI agents to plan, write, execute, and verify code autonomously, closing the loop without requiring the user to act as a middleman at every step.
Agents within Antigravity can evaluate the results of their own code, interact directly with the computer, and generate verifiable “artefacts” such as screenshots or browser recordings for a developer to review and adjust if needed.
Antigravity supports multiple foundation models—including Gemini 3 Pro, Claude Sonnet 4.5, and OpenAI’s GPT-OSS (but not GPT-5 or GPT-5.1)—and is available for Windows, macOS and Linux.
Nano Banana Pro
While all the focus is understandably on the massive leap of Gemini 3 Pro in text and agentic tasks, Google quietly introduced Nano Banana Pro, the image-generation and editing model built on the same underlying architecture. The model, also described as Gemini Image Pro, is designed to bring studio-level precision, control and real-world knowledge into image workflows.
On the downside, Google openly lists limitations. Nano Banana Pro may still struggle with tiny faces, precise spelling in images, accurate representation of complex data in infographics, and advanced edits like blending multiple reference images or executing major lighting transformations. Nano Banana Pro also has to be used with human oversight when accuracy truly matters. AI Explained perfectly illustrated that in his review of Nano Banana Pro. He asks the model to generate an infographic on the spread of Black Death, and although visually it looks good, it is not accurate and can be misleading.
On the topic of accuracy and misinformation, every image generated by Nano Banana is watermarked using Google SynthID, which makes identifying AI-generated images easier.
Nano Banana Pro is available in the Gemini app, and on Google AI Studio and Vertex AI for developers.
Google is winning the AI race
Gemini 3 Pro was released almost exactly to the day three years after ChatGPT entered the stage. The release of ChatGPT caused a massive panic and meltdown inside Google. If anyone was to lead the AI boom, it was to be Google, not OpenAI.
Now, with Gemini 3 Pro, Google is taking the lead in the AI race.
A large part of Google’s advantage comes from its full vertical integration. The company has world-class talent, access to enormous amounts of training data—spanning text, images, video, audio and more—and complete control over the entire compute stack. Gemini 3 Pro was trained entirely on Google’s in-house TPU hardware, as confirmed in the model card, with no reliance on Nvidia GPUs. This enables training larger models and running longer training cycles at a lower cost. Google also substantially scaled up pre-training, increasing both the volume and diversity of the data used. The effect is similar to the earlier leap from GPT-3.5 to GPT-4—the same scaling “dial” turned another significant notch forward.
Right now, Google may be the only organisation capable of training and serving a model at this scale while keeping pricing reasonable, thanks to its tight integration of hardware, data, and infrastructure. With Gemini 3 Pro, Google is now leading the AI race, and with how far ahead Google is compared to the competition, it might take some time for anyone to dethrone Gemini 3 Pro as the best AI model available.

Thanks for reading. If you enjoyed this post, please click the ❤️ button and share it.
Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human.
A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support!
My DMs are open to all subscribers. Feel free to drop me a message, share feedback, or just say "hi!"
Fascinating. The Deep Think explanation was truely eye-opening. It's brilliant how they're tackling reasoning in paralel. Such a smart approach to boost performance!