



Mind over machine? The psychological barriers to working effectively with AI
While AI models are more accessible & capable than ever before, the latest evidence suggests humans aren’t particularly good at using them


It’s been almost a year since the release of ChatGPT and the subsequent explosion of AI-powered tools. These tools, from writing and research assistants to image and code generators, promise to help us do our work more efficiently and augment our skills and creativity. But how good are we at using them?
Isar Bhattacharjee explores this question in his article.
Isar is the founder of Uncover, which provides organisational psychology services for start-ups and scale-ups. He also writes about topics in psychology and the future of work in the Uncover newsletter. This article includes the results from a study he ran over the summer as part of a postgraduate degree at University College London.
Since November 2022, the step-change in accessibility and apparent capabilities from AI models from OpenAI, Google, Inflection and countless other companies have created escalating speculation about their impacts on work (and society more broadly) in the long term. I wrote about my thoughts on some of these long-term trends in one of my first newsletter posts back in February. However, a few months on from my original post, the discussion about these long-term impacts has become pretty saturated.
Instead, fewer people are focusing on the short-term reality of how we are using these tools now. We’re approaching a year on from ChatGPT’s launch and the initial wave of extreme hype has started to pass and user engagement is starting to stabilise - it’s now time to focus on the realities of using AI tools in everyday work.
Effectively using AI at work can have big potential upsides - a paper from March suggests that 19% of the US workforce may have more than half of their tasks impacted by AI. However, being effective when doing so is not straightforward. Ultimately the people using these tools are flawed, and as a result, we exhibit a range of biases in how we approach our use of AI which can limit how effective the gains are. This post will cover the latest evidence on three of these biases.
Problem 1: We don’t know the areas we need the most help with
We are bad at choosing when to use AI models. In a 2019 study, Andreas Fügener and colleagues asked people to classify a number of images of dogs and cats, with one group being offered the option to delegate each decision to an AI model instead of making the classification themselves. This boring, routine classification task (although admittedly not suited to a generative AI model) offers a fairly good proxy for some of the low-stakes delegation we outlined earlier.
They found that participants were not very sensitive to which tasks were the hardest for them to do and so they under-delegated the difficult images (where the human accuracy was the lowest). You would expect the rate of delegation to decrease as human accuracy increases, but you can see that if human accuracy was less than 72% the participants delegated images to the AI model at roughly the same rate.
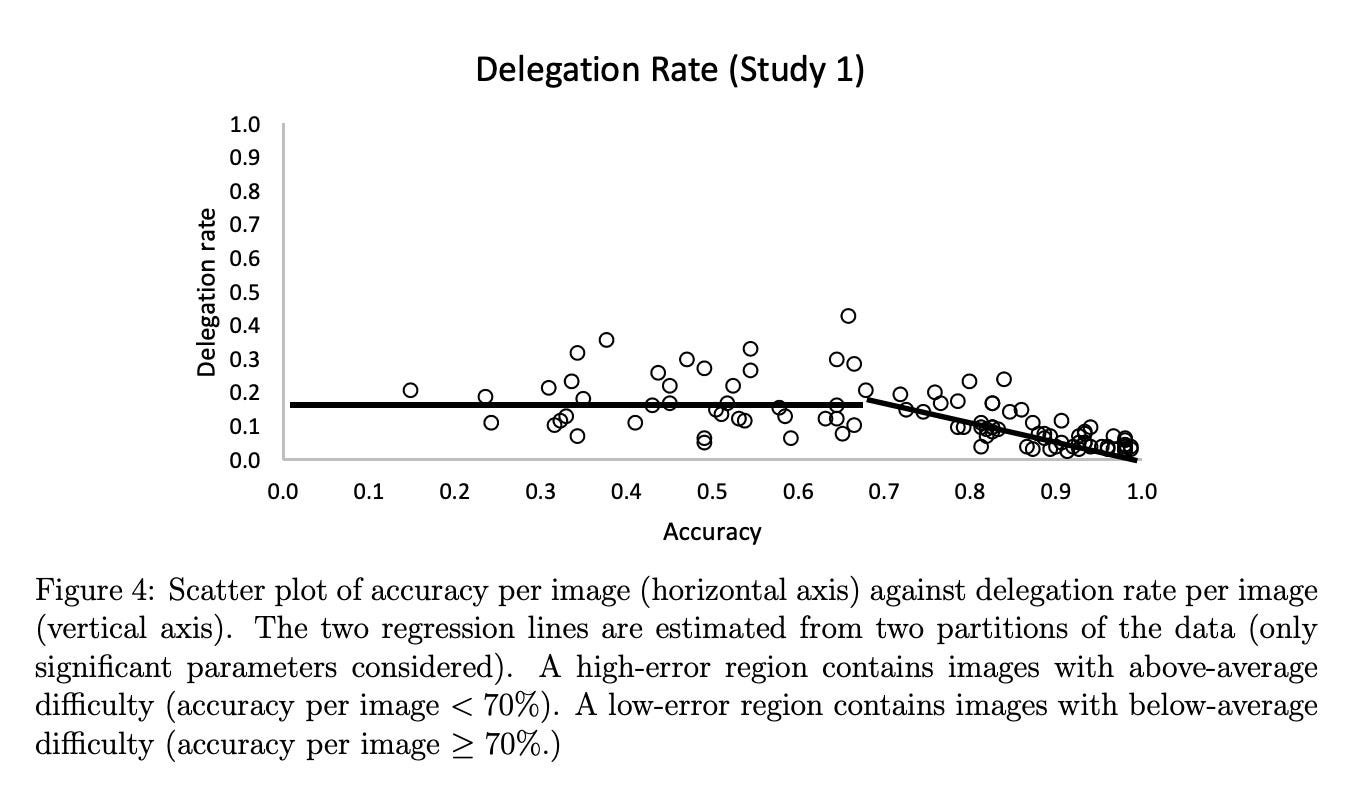
Part of the problem was that participants were not very good at assessing whether their answers were likely to be accurate or not. They would be overconfident in their answers even when their error rates were high, and as a result, didn’t delegate as much as they should have. This ineffective delegation meant those who had access to the AI model did not significantly outperform those who did not have access to the AI model.
The experimenters also had a third condition where the AI model first classifies the image and if the model is not confident in its classification, then the model can delegate the decision to a group of human participants. This condition outperformed the humans significantly, suggesting that models are much better at assessing their performance in tasks than we are!
Okay, so maybe you think this was a result of the people not really understanding the tools they were using. We will cover this more in the “training” section of this post, but training didn’t really help much. In a second related study within the same paper, the experimenters tried to offer training to the participants. They offered people feedback on the first 50 images they received telling them if they had chosen the correct classification or not. This would (in theory) help them calibrate their error rate. The results were clear - the feedback didn’t help the participants delegate more accurately nor did it improve their accuracy in the classification. In the words of the researchers themselves: “It is somewhat disappointing that providing feedback - a common and most intuitive approach – did not create significantly better delegation.”
If you’re sceptical of this paper (perhaps because it’s from 2019), the result has been replicated. A recent BCG study into collaboration with AI tools looked at the tendency of people to align their outputs with suggestions from GPT-4. They found a similar inability for users to assess the tasks which generative AI models would perform better than humans. In fact, the better the outputs from the model the greater the tendency for the human users to modify the outputs - resulting in the end quality of work not reflecting model capabilities.
If you enjoy this post, please click the ❤️ button or share it.
Problem 2: When using an AI model, we take its outputs at face value*
*subject to some nuance
While using AI models can generate, develop or deliver new ideas quickly - we have to be cautious about the quality of end outputs.
The current versions of these models tend to perform better in creative tasks than in complex mathematical or logical reasoning tasks - a finding backed up by the same experimental work by BCG. They found that participants using the AI models outperformed the control group in creative tasks, but under-performed the control group in business problem-solving.

The poor performance in business tasks was interesting - participants with access to GPT-4 were not required to accept the results of the model at face value, yet they continued to rely on the model outputs even when they performed worse than the participants would perform on their own. In informal follow-up interviews many noted that “they found the rationale GPT-4 offered for its output very convincing” even if that rationale was incorrect and only created after the fact to provide ex-post justification for the mistakes made by the model.
This result was quite surprising to me. When we ran our own experiments over the summer we tended to find the opposite result: people were more objective about AI-generated outputs than person-generated outputs. We asked participants to rank the quality of text summaries generated by four separate sources - a university professor, a recent university graduate, GPT-3.5 and a specialist AI model which had been fine-tuned on relevant data. However, in reality, all of the summaries had been generated by GPT-3.5. We found that there were significant differences in how participants rated the “person-generated” summaries, however, the AI-generated summaries were very similarly rated. This suggests that our participants were suffering from the Fundamental Attribution Error when reviewing content made by people, but not when assessing AI-generated outputs. In other words, they judged machines based on their results but they judged people based on their results and their dispositional attributes.
So when we use AI models we don’t assess our work objectively; however, when we look at AI-generated outputs from elsewhere we’re much more objective about their quality. How can we rationalise these two seemingly opposing findings? Well, we aren’t comparing like for like. In BCG’s experiment, the participants are part of the process of creating the outputs. In our experiment, participants reviewed AI-generated work only after it had been created. This difference appears to have a big impact on how you evaluate the quality of outputs. In general, people treat those in their in-group better than they treat someone from outside their group, and they treat items they create or own higher than other equivalent objects. Regardless of whether we see the AI model as a “partner” in the collaboration process or a tool, we’re using to create value, being involved in the creation process makes us less able to objectively assess the end outputs than we would be if we were externally assessing quality. This is an important insight. It implies we should encourage independent reviews of work outputs that were generated by AI and we should be very clear where AI was used in that process.
Problem 3: When things go wrong, people don’t blame the model - they blame you
Accountability becomes tricky when we team with AI models. Earlier this year, a lawyer in the US delegated his case law research to ChatGPT. The results were about what you would expect: the model hallucinated the case examples, the judge was furious, and the lawyers were fined. While this example is a slightly silly instance of over-delegation, I was curious about how people thought about the incident.
As part of the recent experiment I ran, we gave participants a scenario exercise which partially emulated this news report. Participants were given the following scenario:
In 2023, an experienced lawyer in the US used a specialist AI model, LegalAdviceBot, to help prepare the paperwork for one of his clients' cases. Most of the results of the model were accurate, however, there was one crucial inaccuracy in the paperwork generated by the model. The lawyer did not spot the inaccuracy and later this resulted in his client losing the case.
They were then asked to rate how much they blamed the lawyer and how much they blamed the AI model for the client losing the case. Participants overwhelmingly blamed the lawyer more than the model, with a surprising number of participants attributing a blame score of 0 (“No blame at all”) to the AI model.
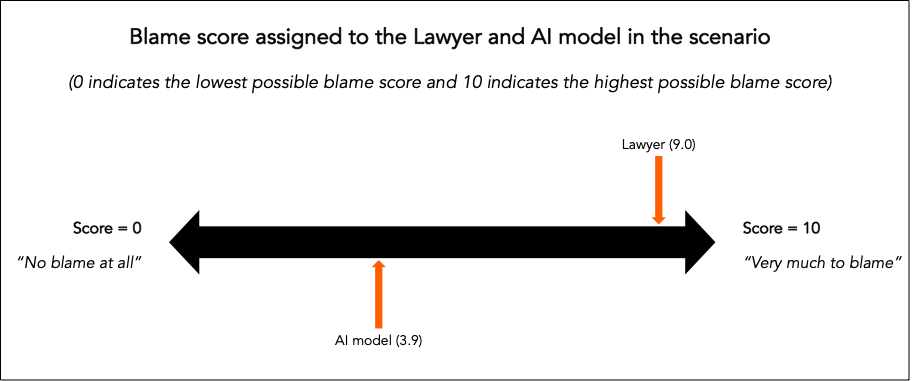
Maybe this isn’t surprising, the lawyer was ultimately responsible for submitting the work to the client, and you might think he shouldn’t be trusting the model in the first place. Well, we tried to put those assumptions to the test in a follow-up scenario:
You later learn that this experienced lawyer paid a tech company a significant amount of money (equivalent to the day-rate of a junior lawyer) to have access to this specialist AI model. Moreover, while the tech company owned this AI model, it was created and trained by several professors from a leading US law school. The lawyer had been provided an assurance that this model was as good as a lawyer, although this assurance was not legally enforceable.
After reading this paragraph, we again asked participants to rank how much they blamed the different agents involved on a scale from 0 to 10.
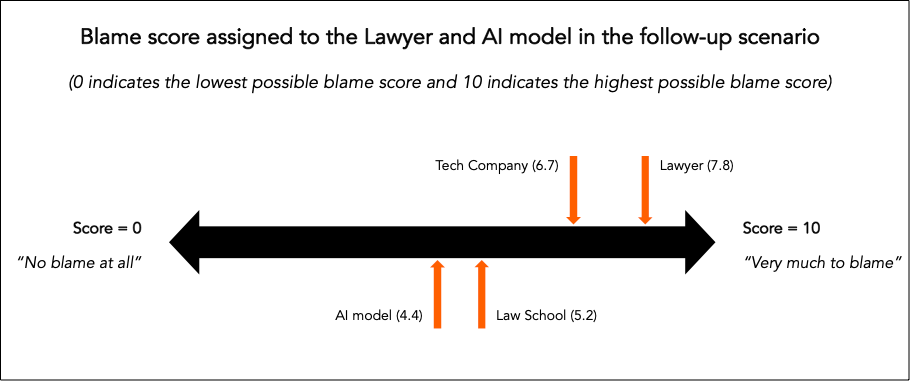
Our hypothesis was, that as the lawyer’s expectations of the model capabilities increased and the wider the set of stakeholders became involved, the blame would shift away from the lawyer. However, despite the emphasis on the model’s capabilities and the fact that the lawyer paid handsomely for access to it, participants still largely blamed the lawyer (and the technology company) for the error. Participants even blamed the law school more than the model, with a whopping 14% of participants giving the model a blame score of 0 (i.e., no blame at all). When it comes to delegated tasks, we don’t blame the model when things go wrong, even if we have good reason to believe the model should be performing well. These blame effects are also especially clear in examples like this when the stakes are high.
Helping people use AI more effectively
Okay, so we aren’t very good at choosing when to use an AI model, we aren’t objective about reviewing its outputs and if things go wrong you’ll be blamed. So how can we make sure we are getting value from the massive productivity potential of these AI models?
Most technology adoption curves have three stages: ready, willing and able. Readiness and willingness relate to an individual’s attitude and approach to the technology, whilst ability relates to the skills that they need to use the technology effectively.
Attitudes - Are people ready and willing to use AI models effectively?
When looking at effective collaboration and delegation in this article, we’ve largely assumed that participants have been uniformly ready and willing to learn how to use AI tools to be more effective. This may be because we - the people writing or reading about AI - are both ready and willing to adopt AI tools. But it wasn’t clear to me how prominent this view was among the wider public. As part of the study I recently ran, we gathered participants’ perspectives about how they saw the potential of AI.
We were pleasantly surprised at the results - a plurality of participants (~50%) expressed positive attitudes towards a future with more AI, with 24% expressing neutral or mixed sentiments and 26% expressing generally negative attitudes. We recruited participants from the general public without prior requirements to have used AI models or have a minimum amount of knowledge about AI. Yet, the participants’ views were fairly sophisticated.

Common positive views included optimism at the degree of knowledge that would become accessible as AI tools proliferated into the mainstream and anticipation of time-saving. This latter view was particularly prominent with over 36% of participants expressing a degree of excitement or anticipation about the time they feel like they can save because of AI. This is a hugely positive finding as these participants are likely to be the most willing and ready to learn how to best use AI.
Concerns about AI centred on a range of issues such as trust and safety worries (such as biases and lack of guardrails) or worries about job replacement. While less common, two negative themes were particularly interesting:
Participants worried about the use of AI tools resulting in more impersonal interactions - either because people were being replaced by AI chatbots or because it would be difficult to know whether you were talking to an AI or a person, resulting in difficulties connecting emotionally with those you’re interacting with.
A small (but not insignificant) group of participants also worried about over-reliance on AI tools, resulting in a loss of skills over time. This was replicated by the BCG research, which showed around 70% of participants had worries about the longer-term impacts of using AI on their creativity.
Overall though, we were pleasantly surprised that a plurality of our participants were feeling optimistic about AI. In particular, the 36% of participants who are excited about productivity gains would presumably be the most motivated to experiment and learn more. So how can we help them?
Training & Enablement - Can we help people to use AI tools more effectively?
For the people who are ready and willing to learn, how can we help them? The traditional answer to enablement challenges is providing training. Providing users with more guidance and teaching them how to use the tool should, in theory, arm them with the understanding to make the most of the tool they are adopting.
However, in practice designing an effective corporate training offering isn’t straightforward (see my post on how we learn for more). The BCG study offered one of their experimental groups a short 30-minute crash course in using GPT-4 and its limitations. They expected to see this group perform better in the business tasks which GPT-4 struggled with. But, they found the opposite! The group with training appeared to perform worse in the business task, potentially because they were over-confidence in their knowledge about the limitations of GPT-4:
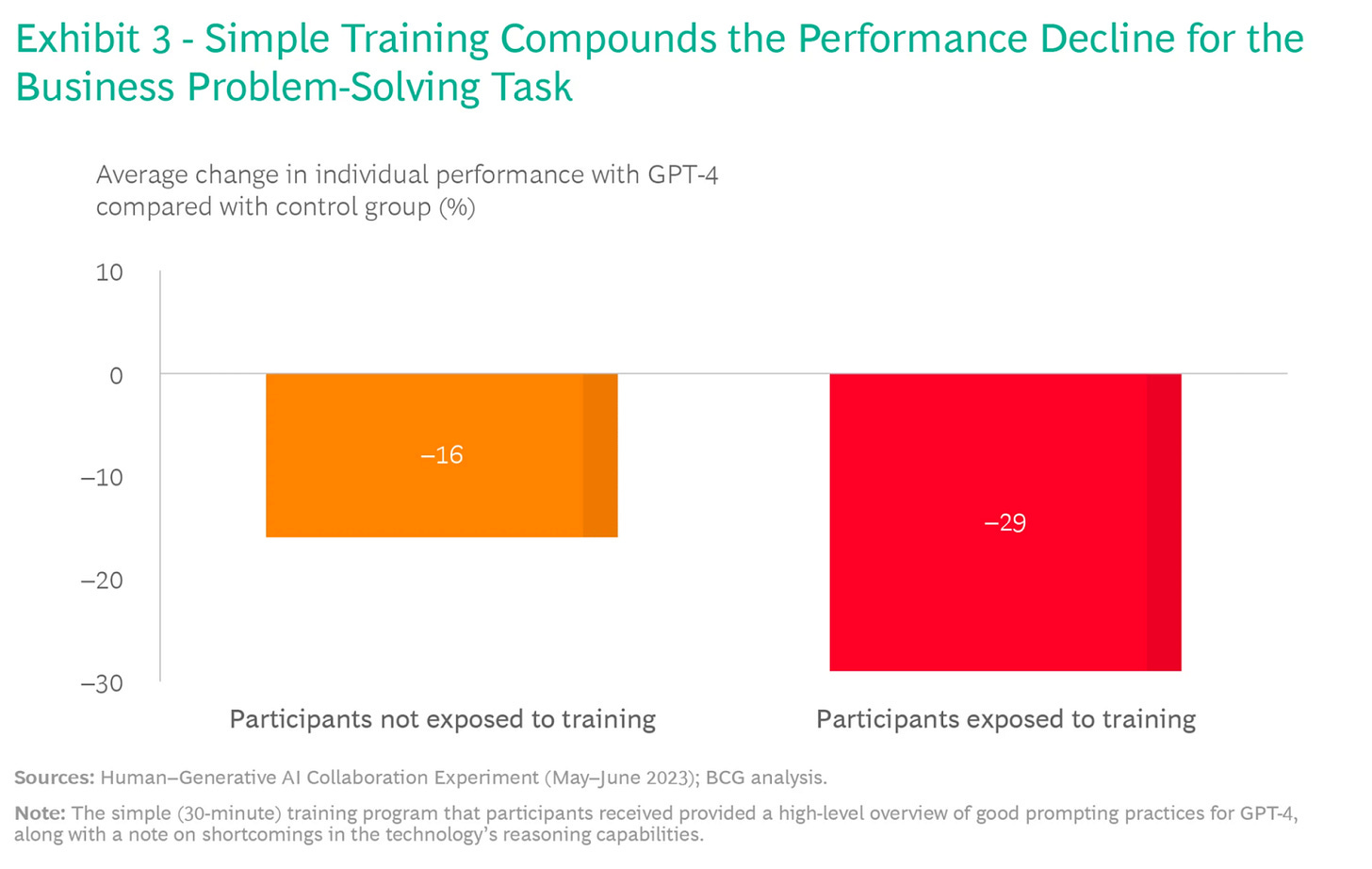
They weren’t the only ones to struggle to find training effective. The 2019 paper we looked at earlier by Fügener et al found that providing feedback to people on a small sample wasn’t enough to change when they delegated to an AI model.
Part of the challenge is that using these AI models effectively is not a function of knowledge, it’s more about skill and process. Skills and concrete changes in how people work are both “harder to teach” in the sense that they are higher in Bloom’s hierarchy of learning. The higher you go the more effort, time and practice required to learn. While a 30-minute class may be enough to help you remember some facts or loosely understand how a model works in principle, it’s likely not enough to apply those learnings or create new processes for how you work.
The Fügener et al study found more concrete changes in processes were more effective at improving the HumanxAI outcomes. In a third study within the same paper, they found more explicit guidance (or guardrails) could change participant behaviour: participants were asked to rate how uncertain they were about the classification of the images - for one group if their certainty was lower than a predefined threshold they were given guidance to delegate the task to the AI model; for another group, if their certainty was lower than the same predefined threshold the task was automatically delegated to the AI. Both of these groups ended up delegating much more to the AI model and improved their performance relative to a baseline where people could freely choose when to use the AI model. This constrained process resulted in a much more effective use of the AI classification model.
Final thoughts and recommendations
So what does this all mean for organisations that want to make the most of AI?
First, use very explicit guidance on when and how to use AI, instead of just giving people a subscription to ChatGPT Plus and letting them roam free. The narrowness gives people less choice - and it’s that choice that leads to ineffective delegation & collaboration. This guidance can be provided by primarily offering tooling within existing platforms such as Github co-pilot, or offering narrower tools which are designed to do one thing really well - for example using products like AutoGenAI for bid writing work. Explicit guidance can also be provided through the use of job aids - e.g., notifications within your existing workflow which prompt you when and how you should use AI models.
Second - don’t rely on short-format classroom learning to teach your employees. We know that doesn’t work very well. It’s not yet clear what types of training will be most effective at improving the use of AI tooling, however, if I were going to speculate the training would involve hands-on practical learning. Either pairing with someone who knows how to use the tools well so you can learn from them as you both work together, or ongoing coaching over time as you experiment with new tools gaining feedback on what works and what doesn’t.
Third, if possible, set up your workflows so that the AI models do a first pass without any human involvement at all. The people who eventually look at those outputs will be more objective than if they did the prompts themselves (fewer endowment effects) and it will counteract our tendency to under-delegate. Alternatively, you can run “red-team reviews” on AI-generated work - where an independent team assesses the quality of work done by an AIxHuman collaboration.
We’re all still in this “test-and-learn” phase of this new wave of tooling, so our understanding will continue to evolve over time. However, we should remain aware of our biases and how they impact the potential value that can be unlocked from AI advances.
Thanks for reading. If you enjoy this post, please click the ❤️ button or share it.
Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human.
A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support!
You can follow Humanity Redefined on Twitter and on LinkedIn.
 | A guest post by
|
Thanks for featuring me! Excited to hear what people think - a lot of this experimental evidence is new so it's of course subject to replication and further research
Good points!